2016 MS SQL HA Cluster
- 5 minutes read - 1000 wordsIntroduction
In our production environment we have a SQL 2016 cluster in HA using availability groups. This is a new (to me) method of providing High Availabilty and comes with significant differences from the SQL 2012 Failover cluster we had before. As I am familiar with SQL and DBA work (but trying not to be our DBA) this is something where I felt I had a bit of a skills gap. Therefore, I am following this UDemy course and these are my notes and insights.
Test Windows Cluster Setup
To get a HA cluster running I needed somewhere to run a few VMs. My home desktop has plenty of resources (24Gb of RAM and fast CPU) which is just about enough but if you have access to a cloud account a few cloud servers would be remove some of the Ops setup work.
You need to get running, 3 Server 2016 boxes. 1 to hold the DC (if you can’t plug into one elsewhere which I can’t on my home network) and 2 more to be the nodes of the SQL cluster. The DC I created as standard settings for Server 2016 VM (50Gb HDD and 4Gb RAM) but for the SQL nodes (which I called SQL1 and SQL2) I doubled the HDD space so there is room for some database files. I bridged the network so they appear connected on my home LAN.
I then installed the Server 2016 Standard GUI install on the three VMs. For the DC, you configure the active directory part from the add roles and features and you need to select “Active Directory Domain Services” role, see screenshot, and then click through the defaults.
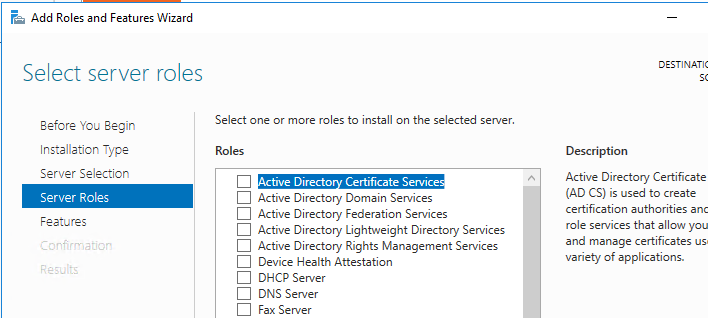
This should also install the “DNS Server” role.
Once the DC was configured (I created a new domain (forest) called sql.test) I added the DC as a DNS server to SQL1 and SQL2 and then added them to the domain. I created a new DCAdmin user and added it to the domain admins group (so that I know I am logining in with a domain account). You then add the Failover cluster feature, see screenshot.
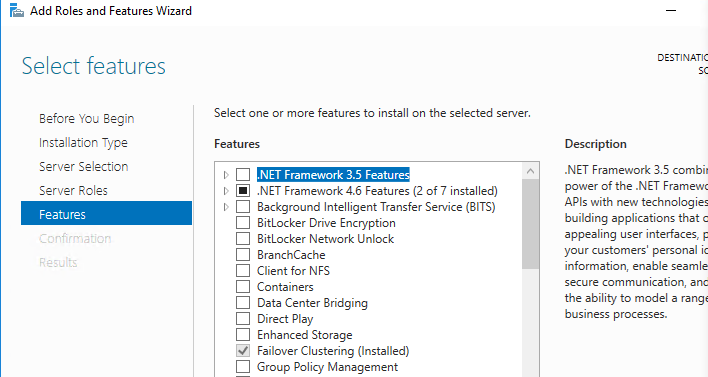
I checked that the Servers were all fully patched and updated… this took a long time.
I created the Cluster of SQL1 and SQL2 using the failover cluster manager tool (Action –> Create Cluster Wizzard). You add both servers comma seperated see screenshot and named it SQLHA.
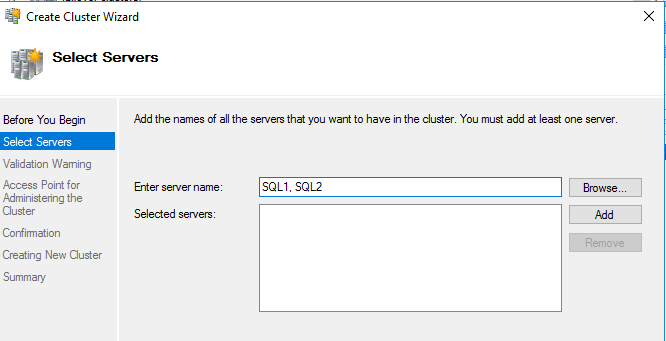
I had to give it a static IP as the DNS I have doesn’t accept dynamic updates like this. Additionally, for the quorum disk, I created a share on the DC for the files. I ignored the warnings about only a single network link between the two nodes of the servers as they are virtualised on the same box (not very HA I know! but this is only production like and not for production).
I also created a domain admin account to run the SQL Servers called TEST\sql. This is not good practice but it will allow me to skip the issues with the SPN registration to the DC at a later point. Two command that come in useful if I want to do this propperly in the future are sp_readerrorlog 0,1,SPN in SSMS to look for SPN registration errors and setspn -L TEST\sql in cmd (admin) to list the registered spn in the DC running as specified user.
Windows firewall is on and blocks SQL connections by default. This is obviously going to be an issue as the nodes will need to talk to each other. So create a inbound rule to allow port 1433 and 5022. This first is the SQL port and the other is a command port for database mirroring. I also had to enable the TCP connection option in the SQL Server Management Console. When installing SQL Server, the installer detected that I was installing on a cluster and allowed me to select the box to enable always on availability groups. If this is missed you can also do this from the SQL Server Management console.
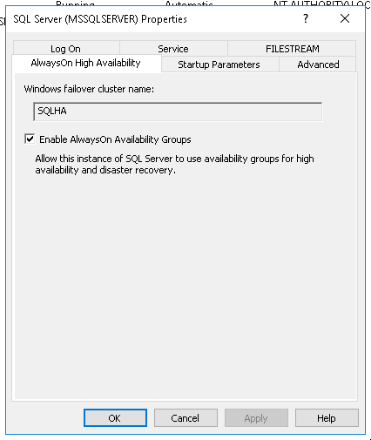
Creating Always on Availability Databases
There are many ways to create a HA cluster and listener, powershell, TSQL or the Wizzard. The Wizzard is the easiest to do and it configures: -
- the database mirroring endpoint
- the listener
- primary and secondary replica settings
- Failover Cluster role
Before you start make sure there is database that meets the pre-requists (has a full backup). The Wizzard starts be defining an name (as most Wizzards do). There is a drop down for type (but I could only select one) and a couple of options (that I should google and find out best practice).
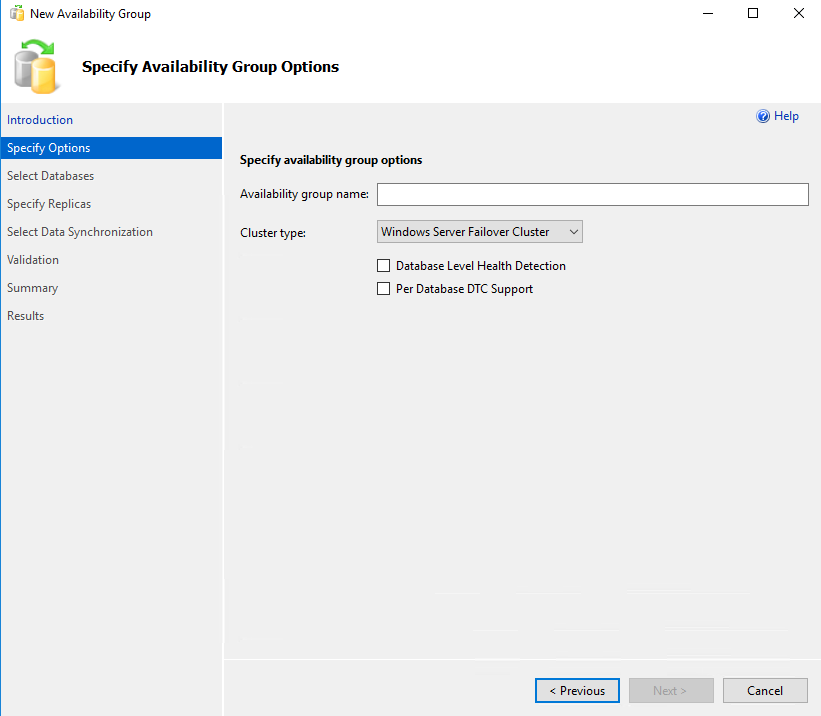
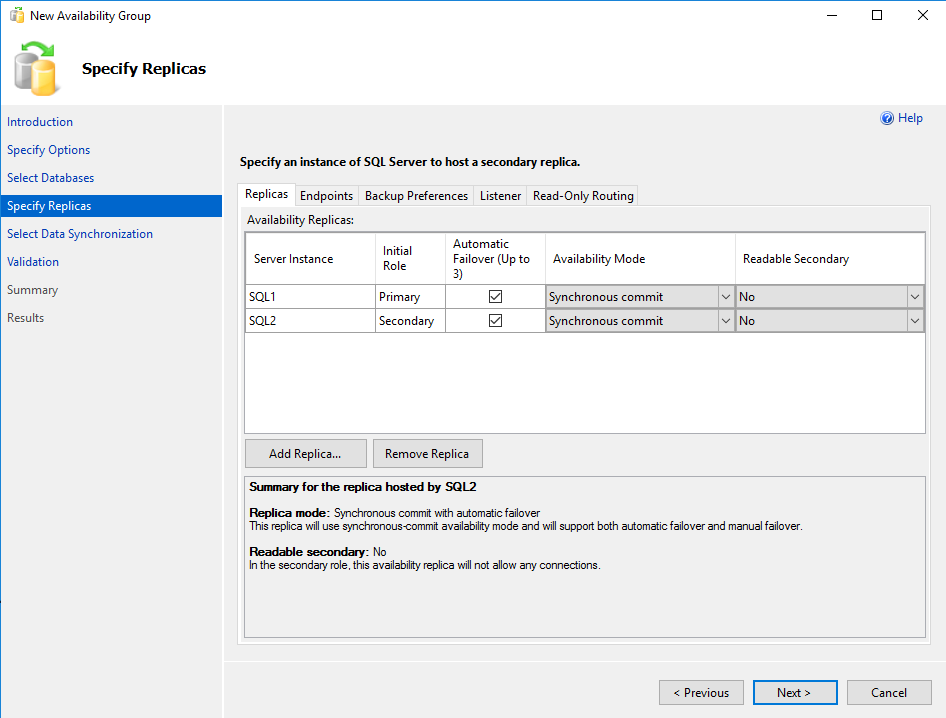
The next step is to select the database you prepared in the previous step before moving on the the replica settings. Failover should be “automatic” for HA (which is not selected as default) and this will change the commit to “Synchronous commit”.
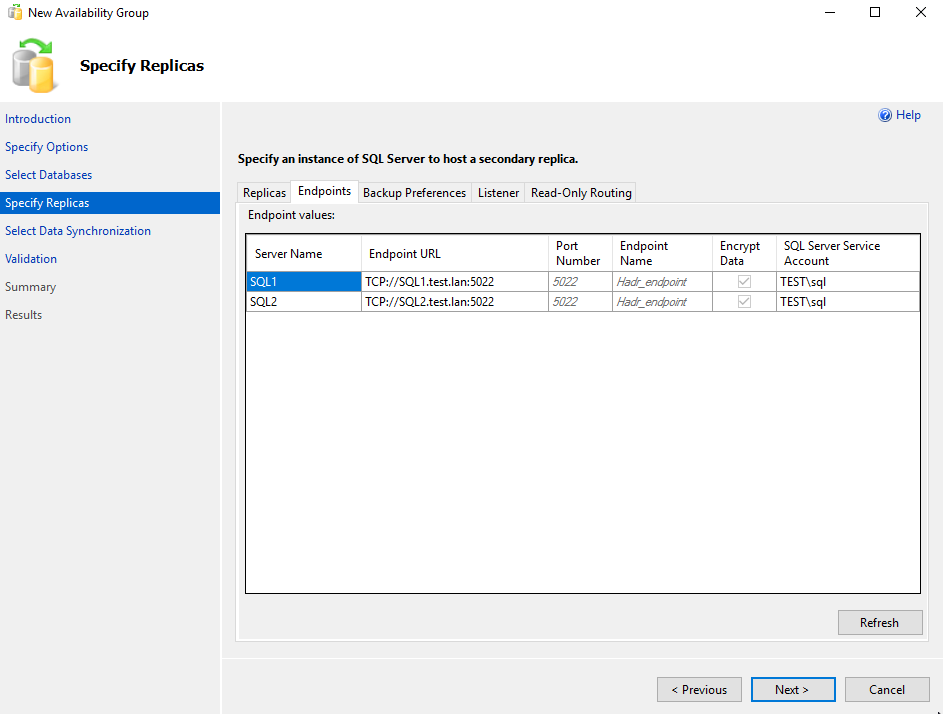
The endpoints will be created if they don’t exist.
We only have a single license in Production so the Backup Preference should be set to “Primary”. Easiest way to get extra performance is to set this to “Prefer Secondary” but I believe this requires an additional license (our Production environment licensing is handled by the hosting provider and we were told not to do this as we would be in breach of the license they have agreed with Microsoft). The listener is created on the fourth tab. Again, in my environment this was created with a static IP.
Powershell Commands
The powershell commands didn’t work on my machine. After some Googling I found that this could be solved by installing a newer module and then importing it. The SQLPS module is no longer being supported but functionality is included in the below SqlServer module.
Install-Module -Name SqlServer
Import-Module SqlServer
Set-Location -Path SQLSERVER:\SQL\<nodename>\<instancename>
Get-Item . | SELECT IsHadrEnabled
Enable-SqlAlwaysOn -Path SQLSERVER:\SQL\<nodename>\<instancename>
Cover Image

Bungalow Flowers
The cover image is one taken of a flower bed at my Grandparents bungalow. Nothing to do with SQL but anyway.